For at opnå de bedste resultater når du laver søgemaskineoptimering, er det vigtigt at du både forstår hvordan en søgemaskine virker, men bestemt også hvorfor de eksisterer.
Lad os starte med den nemme, nemlig hvorfor.
Hvorfor har vi søgemaskiner?
Grunden til Google blev ”opfundet” er ganske simpel; at hjælpe dig med at finde rundt på internettet.
Tænk sig, før søgemaskinerne, skulle man vide hvor man skulle finde informationerne man søgte. Nogle af de første forsøg på at hjælpe dem der brugte internettet, var katalogerne, hvor de mange hjemmesider bliver katalogiseret og struktureret efter emner. Du kunne nemt og hurtigt tilføje din egen hjemmeside til disse kataloger, og på den måde få eksponeret din hjemmeside.
DMOZ
Udfordringerne med disse linkkataloger, er og var at der ikke var nogen måde, at vurdere hvilken af de mange sider, der var den bedste, til at give dig det svar eller information du søgte. Et af de bedste forsøg på at katalogisere internettet er DMOZ, som faktisk stadig eksisterer på https://dmoz-odp.org/
Her finder du næsten 4 millioner sider fordelt på over 1 million forskellige kategorier og underkategorier på 90 forskellige sprog. At vedligeholde et så stort indeks kræver mange redaktører, og på DMOZ var der i slutningen 91.929 godkendte moderatorer.
Det bliver hurtigt meget uoverskueligt og tidkrævende at holde et sådant katalog opdateret, men ikke mindre vigtigt – det skal også være overskueligt og anvendeligt.

I forbindelse med at internettet blev mere tilgængeligt og nemmere at bruge for den ”almindelige” forbruger, eksploderede antallet af domæner på internettet. Derfor lukkede DMOZ officielt ned i starten af 2017, men fortsætter med at leve i forskellige afskygninger, dog bliver det ikke længere opdateret.
Nye domæner
Bare i de første 9 måneder af 2019 blev der angiveligt registreret 24 millioner nye domæner.
FUN FACT: Det vil svarer til at der er oprettet omkring 2.650 domæner i timen, 24 timer i døgnet, hver eneste dag.
Det estimeres at der i starten af 2021 var registreret et sted omkring 2 milliarder domæner, hvoraf det forventes at 400 millioner aktive sider. Det svarer til at 80% af siderne på internettet ikke er aktive, hvilket er et skræmmende højt tal.
Backrub bliver til Google
Der har været flere forsøg på at lave en brugervenlig og effektiv søgemaskine, men Sergei Brin, Larry Page og Scott Hassan fandt den rigtige opskrift til en søgemaskine. Den hedder i dag Google, men startede sin eksistens i 1998 som BackRub og blev først udgivet under navnet Googol, som er et udtryk for et ”et tal” efterfulgt af hundrede nuller. Googol repræsenterede det antal webadresser, også kaldet URL, som søgemaskinen var tiltænkt at skulle gennemsøge.
FUN FACT: Google startede i januar 1996 som et forskningsprojekt på Stanford Universitet i Californien.
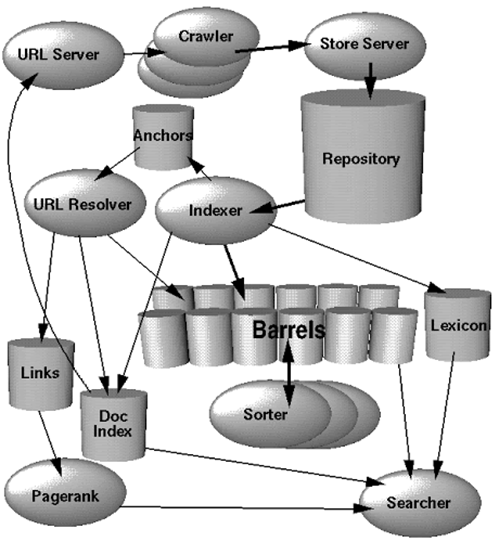
Kilde: The Anatomy of a Large-Scale Hypertextual Web Search Engine
I juni 2000 havde Google søgemaskinen indekseret 1 milliard webadresser (kun 9 nuller) og det var allerede langt foran andre forsøg på søgemaskiner.
I dag er Google den altdominerende søgemaskine, og har fået udtrykket ”at google” med i ordbogen. Grunden til at søgemaskinen blev så populær, skyldes at algoritmen der styrede vigtigheden af et resultat, var langt bedre end andre søgemaskiners. Larry Page valgte et demokratisk koncept til at styre vigtigheden af et resultat, nemlig hvor mange links der pegede på den enkelte side. Den viden blev kombineret med nøgleelementer på den enkelte side, og blev sidenhen kaldt PageRank.
FUN FACT: Den første algoritme blev i 1997 hovedsageligt programmeret af den tredje grundlægger, Scott Hassan, og er i dag stadig, i et vist omfang, en del af den nuværende algoritme.
Kort sagt; en søgemaskine eksisterer for at gøre det uoverskuelige internet anvendeligt. Men hvordan virker den?
Hvordan virker en søgemaskine?
En søgemaskine består af rigtig mange elementer, men en af de vigtigste er en crawler også kendt som en ”Spider”. På dansk kalder vi det en søgerobot, og Google har navngivet deres ”GoogleBot”.
Søgerobotten
En søgerobot gennemtrævler internettet for at lagre de informationer den finder i en kæmpestor database. Måden denne søgerobot finder rundt på internettet, er gennem links, altså når du linker fra én side til en anden side, om det er på dit eget domæne eller ej. Disse links undersøges efterfølgende, og har de nye sider også links – så følges de også og undersøges og så fremdeles. En senere teknologi, kaldet sitemaps, bliver i en vis udstrækning brugt til at definere og identificere de sider som søgerobotten skal igennem på det enkelte domæne. På den måde kan man være sikker på, at søgerobotten formår at finde alle relevante sider for det enkelte domæne. Dette stykke software udvikler sig hele tiden for at følge med i de nyeste teknologier, som hjemmesider kan bygges i.

GoogleBot er specielt opmærksom på at finde nyt indhold, ændringer til eksisterende indhold og nedlagt indhold. En algoritme vurderer ud fra eksisterende erfaringer med siden, hvor ofte det er nødvendigt at komme tilbage og gennemsøge siden igen, men også hvor mange sider der skal hentes fra den enkelte side. Jo oftere der sker ændringer på siden, jo oftere er det nødvendigt at komme tilbage, for at opdage og identificere det nye indhold.
Google demokratiet
Da også GoogleBot er et demokratisk stykke software, er det muligt at styre hvad og hvor meget du tillader søgerobotten at kigge på.
- Du kan vælge at søgerobotten at læse indholdet, men ikke følge links på siden.
Dette gøres ved at anvende meta content nofollow – LINK
Det er også muligt at definere nofollow på de individuelle links – LINK - Du kan tillade søgerobotten at følge links på siden, men ikke medtage den i deres indeks
Dette gøres ved at anvende meta content noindex – LINK - Du kan fortælle robotten at holde sig helt væk
Dette gøres i en fil kaldet robots.txt – LINK - Du kan fortælle robotten at tage det lidt med ro, og begrænse crawlrate – LINK
De ovenstående teknologier kan i flere tilfælde kombineres. Det giver dog ikke mening at sætte nofollow eller noindex, hvis søgerobotten er forment adgang i robots.txt da den ikke vil kunne læse informationen til at begynde med. Det betyder også at du ikke kan styre indekseringen, hvis du udelukker adgangen i robots.txt
Hvis du er interesseret i statistik over hvor ofte en GoogleBot kommer forbi din side, er det bare opsætte en konto på Google Search Console, tidligere kaldet Webmaster Tools. Heri kan du under ”Indstillinger” finde elementet ”Statistik for crawl” der viser statistiske data for de seneste 90 dage.
Algoritmen
Google har udviklet en algoritme til at vurdere det indhold som søgerobotterne indsamler, så der kan opstilles en prioritering over hvilke sider der er det bedste resultat på en given forespørgsel.
På meget få millisekunder finder algoritmen de 10 bedste resultater til dig blandt de flere hundrede milliarder muligheder der er på internettet.
Faktisk består vurderingssystemet af flere algoritmer, som måler på et utal af forskellige målepunkter. Resultatmulighederne bliver vurderet på rigtig mange målepunkter, heriblandt relevans i forhold til din forespørgsel, resultatets anvendelighed, sidens troværdighed og popularitet. Hvert enkelt målepunkt bliver efterfølgende vægtet i forhold til din tidligere færden på internettet og din aktuelle placering. Det betyder også at du kan få et andet resultat end din fætter i den anden ende af landet.

Google prøver at forstå dig
Hver enkelt algoritme har et specifikt ansvarsområde, og en af dem der udvikler sig voldsomt i øjeblikket, er den der håndterer forståelsen af din forespørgsel. At forstå dine intentioner når du søger på nettet, er ikke nemt for et stykke software. Hvad menes der eksempelvis med ordet ”skifte”?
- Udskifte – Hvordan skifter jeg en pære?
- Arveret – Hvordan skifter man bo?
- Justere – Hvordan skifter jeg baggrundsbillede på min telefon
Normalt søges der med meget få ord, så muligheden herover for ”justere” bliver oftest udført således ”skifte baggrund iPhone”. Derudover skal algoritmen også kunne genkende og forstå dine stavefejl.
Rankbrain
I midten af 2016 introducerede Google algoritmen RankBrain, som var den første maskinlæringsalgoritme der skulle hjælpe med at forstå det naturlige sprog brugt i udførte søgninger.
Bert
I oktober 2019 introducerede Google algoritmen Bert, som var den første udvidelse af sprogforståelsen. Det er Googles neurale netværksbaserede teknik til præ-træning af NLP (Natural Language Processing) og den første teknologi der gennem Artificial Intelligence (AI) forstår sammenhængen mellem forskellige sprog.
FUN FACT: Det vurderes at der laves flere end 500 ændringer til algoritmerne om året.
Google MUM
Den seneste opdatering til algoritmen der håndterer området, kalder Google MUM, og kaldes en milesten for anvendelsen af AI til sprogforståelse. Det siges at MUM er 1.000 gange mere kraftfuld og effektfuld sammenlignet med BERT. Ydermere dækker MUM ikke kun tekstuelt indhold, men arbejder også på at forstå indhold af såvel billeder, video og audio, vel at mærke på tværs af flere end 75 sprog.
Det vurderes at der er 3,5 billioner søgeforespørgsler på Google hver dag. På årsbasis vurderes det at 16-20% ikke har været udført tidligere, hvilket stiller store krav til forståelsen af hensigten bag.
Søgeresultatet
Da Larry Page i starten af projektet skulle beskrive den perfekte søgemaskine, valgte han at gøre det kort:
Den perfekte søgemaskine er et værktøj, der forstår præcis hvad du mener og leverer hurtige svar på lige nøjagtigt det du søger.
Der er også sket rigtig meget i forhold til måden resultaterne vises på. Tidligt i processen, viste søgeresultatsiden blot 3 informationer, nemlig webadressen, sidens title og metabeskrivelsen.
Nogle af os kan huske dette billede.
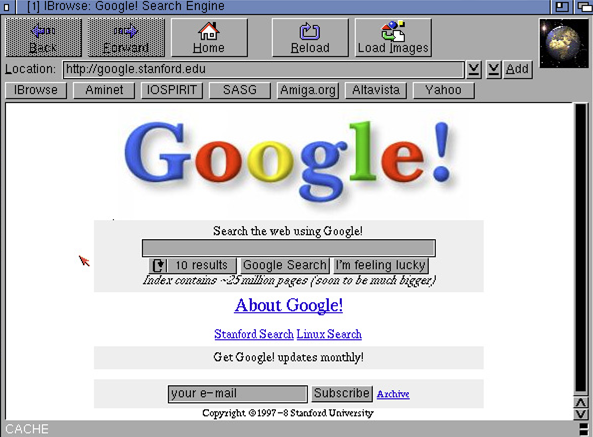
Billedet er fra 1998, og der var omkring 25 millioner sider i Google database.
I september 2001 var der over 1,6 milliarder sider i deres database.
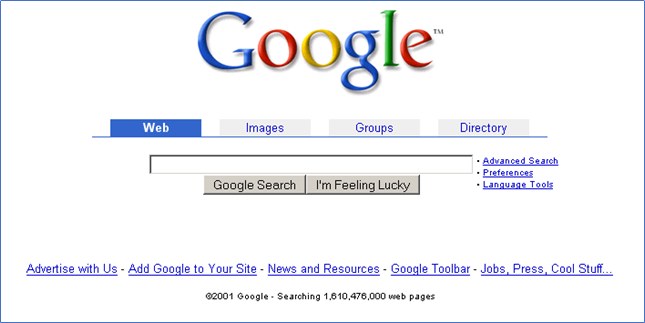
I 2014 var der 35 trillioner sider i deres indeks og i 2016 var tallet oppe på at have 130 trillioner. Det vurderes at tallet i 2020 var oppe på 17,5 kvadrillioner (der er 24 nuller i en kvadrillion)
Der er altså stadig langt op til en Googol indekserbare sider, og spørgsmålet er om de nogensinde når dertil.
Google 2022
I dag er det muligt at få meget mere information med ud i søgeresultaterne, og mange flere muligheder for at få dine resultater vist.
Du kan få et billede, prisen, lagerstatus, specifikationer og anmeldelser med ud på en produktvisning.
Nedenstående er nok ikke det bedste eksempel, men der er masser af ekstra info.
Men der også flere muligheder end det ”almindelige” resultat, men det er et emne til en helt anden guide.
Vi tager dog lige et par eksempler.
Det langt mere hensigtsmæssigt og brugervenligt at vise dig vejrudsigten direkte i søgeresultatet, end at linke til udbydere af vejrudsigter. Stiller du spørgsmålet ”Hvor højt er Rundetårn” er det også en bedre brugeroplevelse at vise det direkte på Google. (Svaret er ikke 35 meter som Google har misforstået, men 41,55 meter jf. Wikipedia)
Søger jeg eksempelvis på ”pizza” får jeg resultater på et kort, som viser hvor de nærmeste pizzeriaer ligger. Jeg får også fakta om en pizza fra en troværdig kilde. Der ligger opskrifter på en pizza og forskellige spørgsmål der henvender sig til søgningen. Jeg får også muligheder for at se videoer og billeder samt reklamer fra Google Ads. Grunden til resultatsidens forskellighed er at det ikke kan defineres hvad min intentioner er bag søgningen.
Søger jeg i stedet på ”ny iphone”, så er resultatsiden en helt anden. Der er flere, og mere prominent placerede, reklamer fra Ads, men også resultater fra Google Shopping. De organiske resultater er præget af udbydere af telefoner fra Apple, men også anmeldelser af de forskellige modeller.
Jo mere præcis min søgning bliver, jo bedre bliver resultaterne, og jo mere faktabaseret søgningen bliver, jo færre reklamer bliver vist. Søgeresultatsiden for søgningen ”hvem vandt VM i herrehåndbold 2021” indeholder ikke en eneste reklame.
Der har været meget udvikling på optimeringen af resultatsiderne for hoteller og flyrejser. Søg eksempelvis på ”fly fra Aalborg til København” eller ”hotel i Aalborg”. Tidligere så man resultater i form af ”almindelige” resultater, men nu visers resultaterne direkte på søgemaskine resultatsiden (hvilket i fagtermer hedder SERP)


Den udvikling forventer jeg vil sprede sig til endnu flere områder.
FUN FACT: Den første hjemmeside blev udgivet i 1991 af Tim Berners-Lee, en fysiker på atomforskningsinstituttet CERN, men først i 1995 blev det offentligt tilgængeligt at oprette en hjemmeside. Internettet som vi kender det, er altså ikke meget mere end 25 år gammelt.
Hvad er en søgemaskine om 25 år
Se – det er et rigtig godt spørgsmål.
Mit bud er at der stadig vil være en eller anden form for søgemaskine, men jeg er dog i tvivl om hvorvidt den bliver visuel og på internettet, som vi kender den i dag. Der skal nok komme en ny konkurrent på markedet som har et bedre produkt end Google. Mit bud er at vi ikke længere ”googler” til den tid. Søgemaskinen hedder højest sandsynligt ikke længere en søgemaskine, for den ved allerede hvad du har tænkt, så det er en forudsigelsesmaskine.
Vi har alle set Sci-Fi film, hvor den store alvidende computer har svaret på ALT, om så svaret er 42 eller noget helt andet, må fremtiden vise. Det kunne være at vi alle lever i et selvlærende SkyNet computernetværk på ren Matrix vis, hvor alle beslutninger allerede er taget.
Tanken om at vi bevæger os rundt i en stemmestyret (eller endnu vildere – tankestyret) virtuel verden (AR – Argumentet Reality), er ikke utænkelig, som i Surrogrates fra 2009.
Hvad end virkeligheden bliver om 25 år, så er det med garanti endnu vildere end forudsigelserne i de mange Sci-Fi film.
Jeg ved fremtiden kommer, men hvor vi er om bare 5 år, er svært at spå om, men her er et godt bud: https://searchengineland.com/web-crawling-history-383908
Kildehenvisninger:
- https://www.google.com/search/howsearchworks/
- https://hostingtribunal.com/blog/how-many-websites/
- https://www.versionmuseum.com/history-of/google-search
- https://en.wikipedia.org/wiki/Larry_Page